For the Computer Operating Environments module we had to create a multi-threaded program and measure the performance characteristics of a variety of different threads. There were certain requirements such as sharing resources or signalling between threads, but what the application actually did was up to us.
I knew I wanted to keep the application fairly simple since complexity and scale wouldn't get me any extra marks and would just make development more difficult. So I decided to do a follow up to the spacial partitioning system in the twin-stick shooter I made on PlayStation Vita in the first semester. That system divided up space in a regular fashion but I knew that a much more efficient way to do it would be to divide based on density of objects. If there is a large empty space then that should be represented as a single space, whereas if there is a small area with lots of objects then it should be divided into multiple smaller spaces. This all led me to quad trees.
A quad tree is essentially just a container with a size limit. If the size limit is breached then the tree subdivides into four sub-trees. This recursive structure can be used to efficiently divide a space based on the density of the objects within it.
I knew I wanted to keep the application fairly simple since complexity and scale wouldn't get me any extra marks and would just make development more difficult. So I decided to do a follow up to the spacial partitioning system in the twin-stick shooter I made on PlayStation Vita in the first semester. That system divided up space in a regular fashion but I knew that a much more efficient way to do it would be to divide based on density of objects. If there is a large empty space then that should be represented as a single space, whereas if there is a small area with lots of objects then it should be divided into multiple smaller spaces. This all led me to quad trees.
A quad tree is essentially just a container with a size limit. If the size limit is breached then the tree subdivides into four sub-trees. This recursive structure can be used to efficiently divide a space based on the density of the objects within it.
Depth
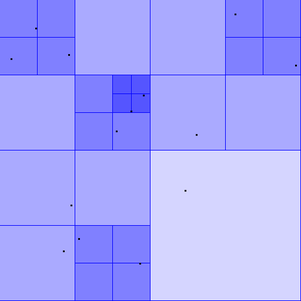 |  |
In the screenshot on the left are sub-trees at a number of different depths. The entire window is itself a quad tree known as the root. Every other tree is a sub-tree of the root. The root tree has a depth of zero and each subsequent subdivision increases the depth by one, for example the bottom right quarter is a tree at a depth of one.
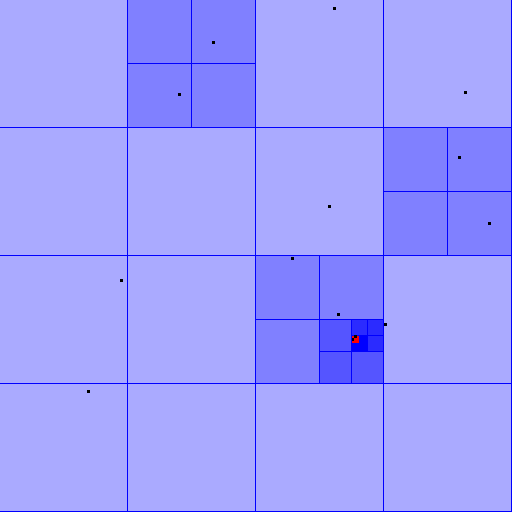
This video is a good example of a quad tree at work and also inspired me to change the colour of the trees based on their depth (deeper trees are darker). For my system I made the size limit for the trees one, meaning that a tree can have zero or one visitors (the black dots) but if it got a second it would subdivide. If two visitors happened to cross paths exactly it would infinitely subdivide and crash the program, so I added a maximum depth for the trees. If a tree at the maximum depth gains a second visitor it will flash red to show the 'collision', as seen in the screenshot on the right.
I used SFML (2.1) for the graphics side of things.
This video is a good example of a quad tree at work and also inspired me to change the colour of the trees based on their depth (deeper trees are darker). For my system I made the size limit for the trees one, meaning that a tree can have zero or one visitors (the black dots) but if it got a second it would subdivide. If two visitors happened to cross paths exactly it would infinitely subdivide and crash the program, so I added a maximum depth for the trees. If a tree at the maximum depth gains a second visitor it will flash red to show the 'collision', as seen in the screenshot on the right.
I used SFML (2.1) for the graphics side of things.
Updating and rendering the structure using multiple threads
For the threading side of things I used the Boost library (1.54.0).
I made simple classes for a semaphore and a channel so that I could have a buffer of visitors and safely track how many elements the buffer had when multiple threads were accessing it. When a new visitor is added to the system it is simply written to the channel and inserted into the tree structure by another thread (more on that later).
Every frame begins by updating the structure, which (like all operations involving the tree structure) is a recursive process starting at the root. Whenever a visitor is found it's position is updated based on it's velocity. This updated position is then checked to see if it is still within the bounds of the current tree. If the visitor is no longer in the correct tree it is removed and written to the channel. If a tree has sub-trees then each of those is updated in turn and the number of visitors in each is summed. If this sum is zero then there is no need for the sub-trees any more so they are removed. If the sum is less than or equal to the limit for a single tree then the sub-trees are still not required and are removed, but not before pulling all the visitors back up to the local root. This helps keep the structure at a minimal size.
While one thread is updating the structure another is polling the channel for insertion jobs. Whenever a visitor is pushed into the channel's buffer it is then read by the insertion thread and added to the tree structure. The insertion is rather simple and starts (as always) at the root. If the current tree has no sub-trees and the current visitor is within the bounds of the tree, insert it into that tree. If the tree then has more visitors than the limit it will either subdivide or (if at maximum depth) flag the collision. If the tree does have sub-trees then check the bounds for each and insert the visitor accordingly.
Once the structure has been updated and all insertion jobs have completed, the rendering begins. This is another very simple process thanks to the recursive nature of the structure. Starting at the root it simply renders the tree and either renders it's visitors (if it has any) or calls the render function for each sub-tree (if it has any). Note that a tree cannot have both visitors and sub-trees at the same time.
Below is a UML class diagram showing the classes made for this application as well as their members and data. All data is private.
I made simple classes for a semaphore and a channel so that I could have a buffer of visitors and safely track how many elements the buffer had when multiple threads were accessing it. When a new visitor is added to the system it is simply written to the channel and inserted into the tree structure by another thread (more on that later).
Every frame begins by updating the structure, which (like all operations involving the tree structure) is a recursive process starting at the root. Whenever a visitor is found it's position is updated based on it's velocity. This updated position is then checked to see if it is still within the bounds of the current tree. If the visitor is no longer in the correct tree it is removed and written to the channel. If a tree has sub-trees then each of those is updated in turn and the number of visitors in each is summed. If this sum is zero then there is no need for the sub-trees any more so they are removed. If the sum is less than or equal to the limit for a single tree then the sub-trees are still not required and are removed, but not before pulling all the visitors back up to the local root. This helps keep the structure at a minimal size.
While one thread is updating the structure another is polling the channel for insertion jobs. Whenever a visitor is pushed into the channel's buffer it is then read by the insertion thread and added to the tree structure. The insertion is rather simple and starts (as always) at the root. If the current tree has no sub-trees and the current visitor is within the bounds of the tree, insert it into that tree. If the tree then has more visitors than the limit it will either subdivide or (if at maximum depth) flag the collision. If the tree does have sub-trees then check the bounds for each and insert the visitor accordingly.
Once the structure has been updated and all insertion jobs have completed, the rendering begins. This is another very simple process thanks to the recursive nature of the structure. Starting at the root it simply renders the tree and either renders it's visitors (if it has any) or calls the render function for each sub-tree (if it has any). Note that a tree cannot have both visitors and sub-trees at the same time.
Below is a UML class diagram showing the classes made for this application as well as their members and data. All data is private.
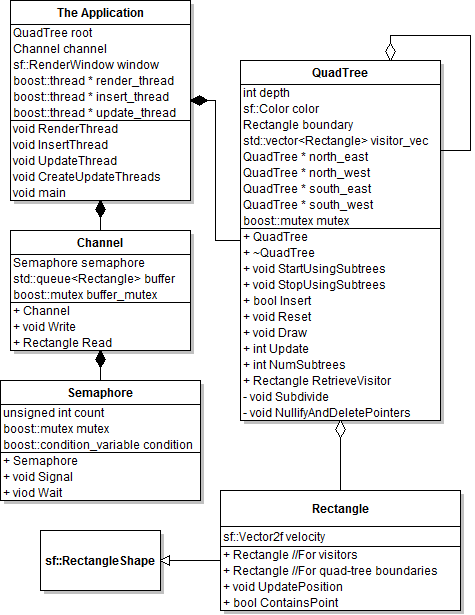
UML class diagram for the program. 'The Application' is just the main.cpp file but I included it to show how it relates to the classes
Below is a top-level UML activity diagram showing the control flow of the program.
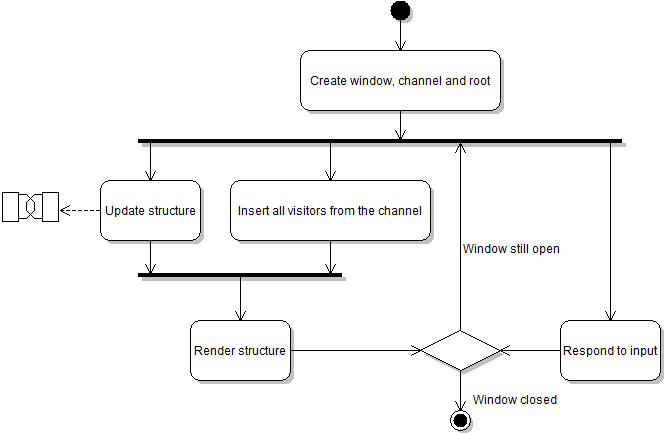
As you can see there is a fourth and final long-running thread which handles user input. This is done in the main thread after setting everything up and starting the other threads. The 'Update structure' section is detailed a bit further on.
Measuring performance and varying the number of threads
With four long-running threads the program works very well on a quad-core processor (or hyper-threaded dual-core like on the laptop I made this on), easily staying above 60 FPS with several hundred visitors in the structure. But as part of the coursework we had to vary the number of threads and measure and compare the performance, explaining why the program ran best on X threads.
After discussing with my lecturer how I could vary the number of threads, we came to the conclusion that I needed to use more threads even though I knew it would hurt performance, so that I could explain why. Having realised I don't need to use lots of threads well, I just need to use them in some capacity, I figured in for a penny, in for a pound and promptly set about destroying performance.
Each tree has a depth in the structure and by definition has exactly zero or four sub-trees. I added a 'sub-thread depth' which can be changed at run time and starts at -1 (none). When updating the structure, the tree's depth is checked against the sub-thread depth. If the tree's depth is less than or equal to the (non-negative) sub-thread depth and it has more than four sub-trees (meaning it has sub-trees and at least one of those sub-trees has sub-trees) it will create four new threads. Each of those threads will then take a sub-tree and run the same check. If the tree's depth is greater than the sub-thread depth or it has four or less sub-trees it is simply updated as described above. This is explained diagrammatically below:
After discussing with my lecturer how I could vary the number of threads, we came to the conclusion that I needed to use more threads even though I knew it would hurt performance, so that I could explain why. Having realised I don't need to use lots of threads well, I just need to use them in some capacity, I figured in for a penny, in for a pound and promptly set about destroying performance.
Each tree has a depth in the structure and by definition has exactly zero or four sub-trees. I added a 'sub-thread depth' which can be changed at run time and starts at -1 (none). When updating the structure, the tree's depth is checked against the sub-thread depth. If the tree's depth is less than or equal to the (non-negative) sub-thread depth and it has more than four sub-trees (meaning it has sub-trees and at least one of those sub-trees has sub-trees) it will create four new threads. Each of those threads will then take a sub-tree and run the same check. If the tree's depth is greater than the sub-thread depth or it has four or less sub-trees it is simply updated as described above. This is explained diagrammatically below:
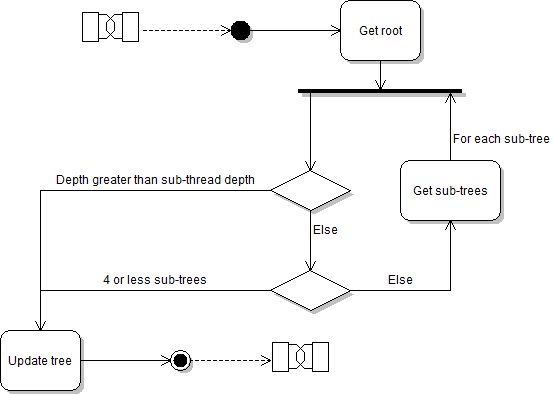
Detail of the 'Update structure' section from the activity overview
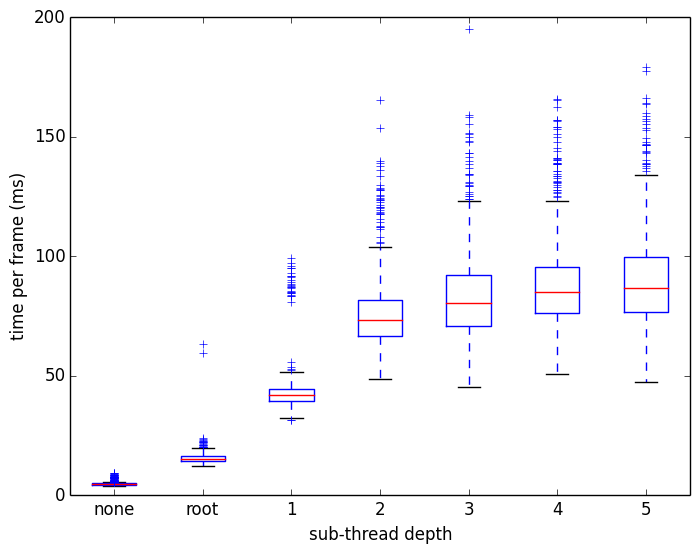
As you would imagine this makes the program perform terribly due to the overhead of creating and destroying all those threads every frame. In fact the possible number of threads created each frame increases exponentially with each increment of the sub-thread depth, due to the way the structure subdivides. This is evidenced by the graph below, which shows the recorded frame times for 1000 consecutive frames with the same 100 visitors in the system, over a variety of sub-thread depths.
The same data on a logarithmic scale clearly shows the exponential nature of the increase in frame time:
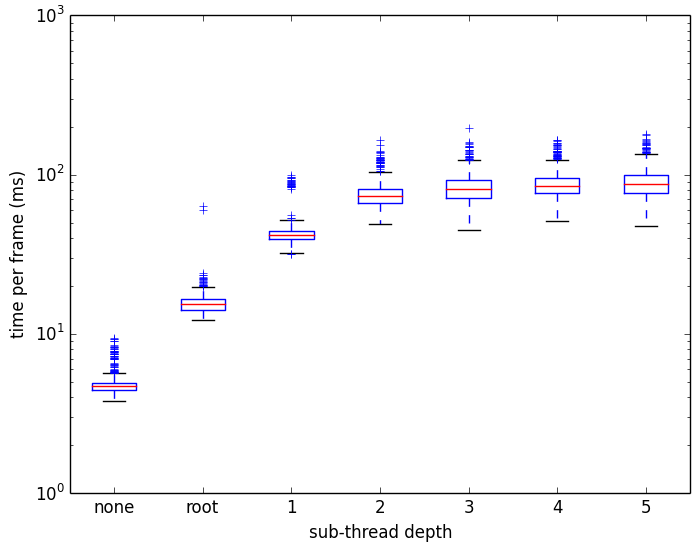
The results begin to level out at a sub-thread depth of 2, because at that point there aren't enough quad-trees at a high enough depth to cause many more threads to be created. These graphs were made using the matplotlib python library.
Clearly the best performance occurs when not creating any additional threads each frame. This is partly because the benefits of spreading the work of updating the structure are so far outweighed by the overhead of creating and destroying so many threads each frame. But it also has to do with the fact that the CPU used for testing could only run four simultaneous threads. Since the application already has four long-running threads, the CPU has to share time and resources between those threads and the additional update threads.
Having successfully murdered performance and been able to explain why, I was pretty happy with the project overall. It looks pretty cool when there are lots of visitors in the system and it's a nice evolution of the spacial partitioning system I made in the previous semester.
If you missed the link before, you can download and run the application for yourself here.
Clearly the best performance occurs when not creating any additional threads each frame. This is partly because the benefits of spreading the work of updating the structure are so far outweighed by the overhead of creating and destroying so many threads each frame. But it also has to do with the fact that the CPU used for testing could only run four simultaneous threads. Since the application already has four long-running threads, the CPU has to share time and resources between those threads and the additional update threads.
Having successfully murdered performance and been able to explain why, I was pretty happy with the project overall. It looks pretty cool when there are lots of visitors in the system and it's a nice evolution of the spacial partitioning system I made in the previous semester.
If you missed the link before, you can download and run the application for yourself here.
 RSS Feed
RSS Feed
